Non-linearity in the classical regression model and basics on moderation
The world can be non-linear
At this point you probably remember the notion of linearity in the Classical Regression Model.
It is a important assumption in the Classical Regression Model, but it is not a strict assumption. This is a good characteristic of the linear model.
Multiple phenomena in the universe are not linear such as growing curves, or developing curves in human beings are many times not linear at all.
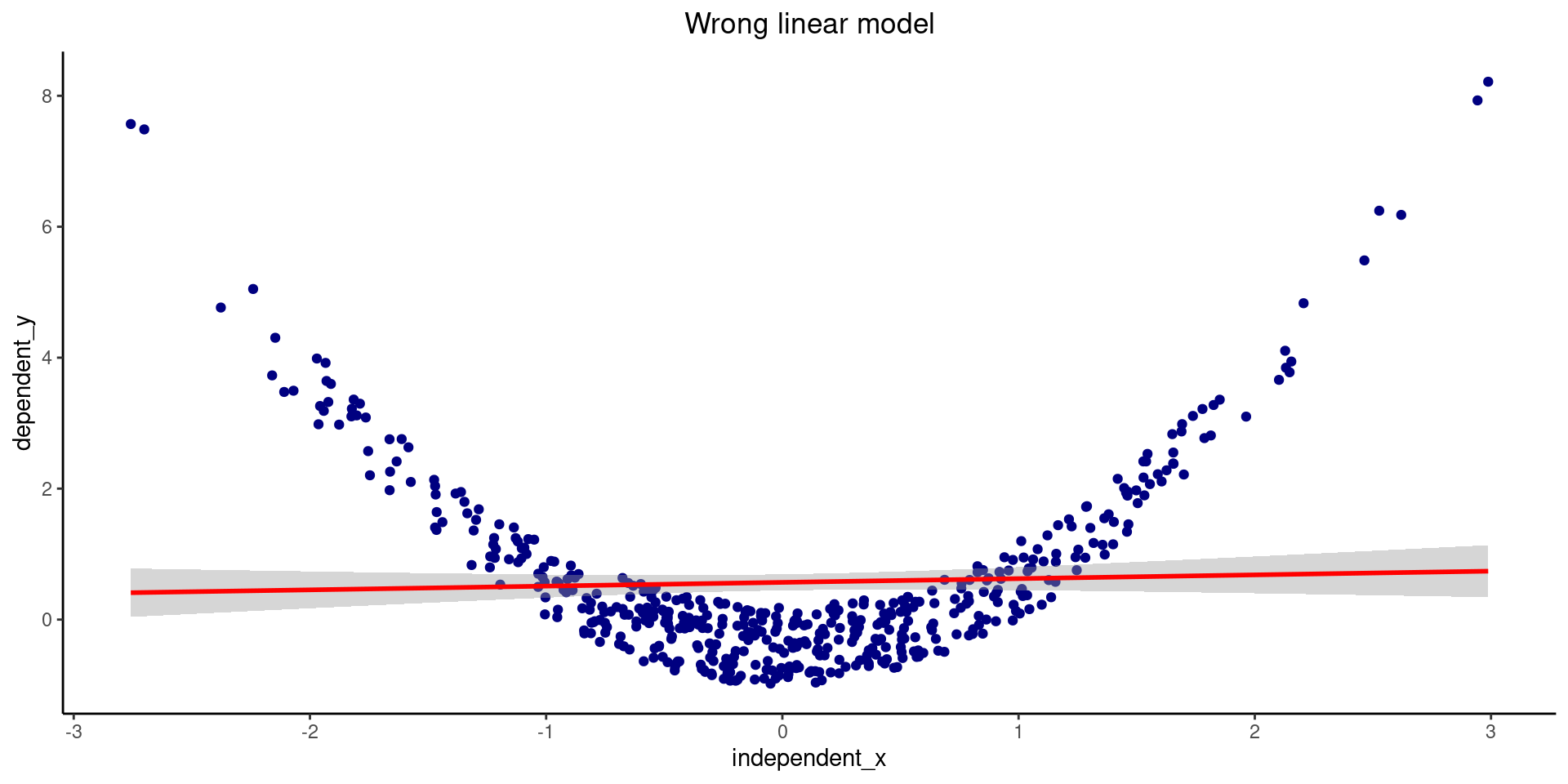
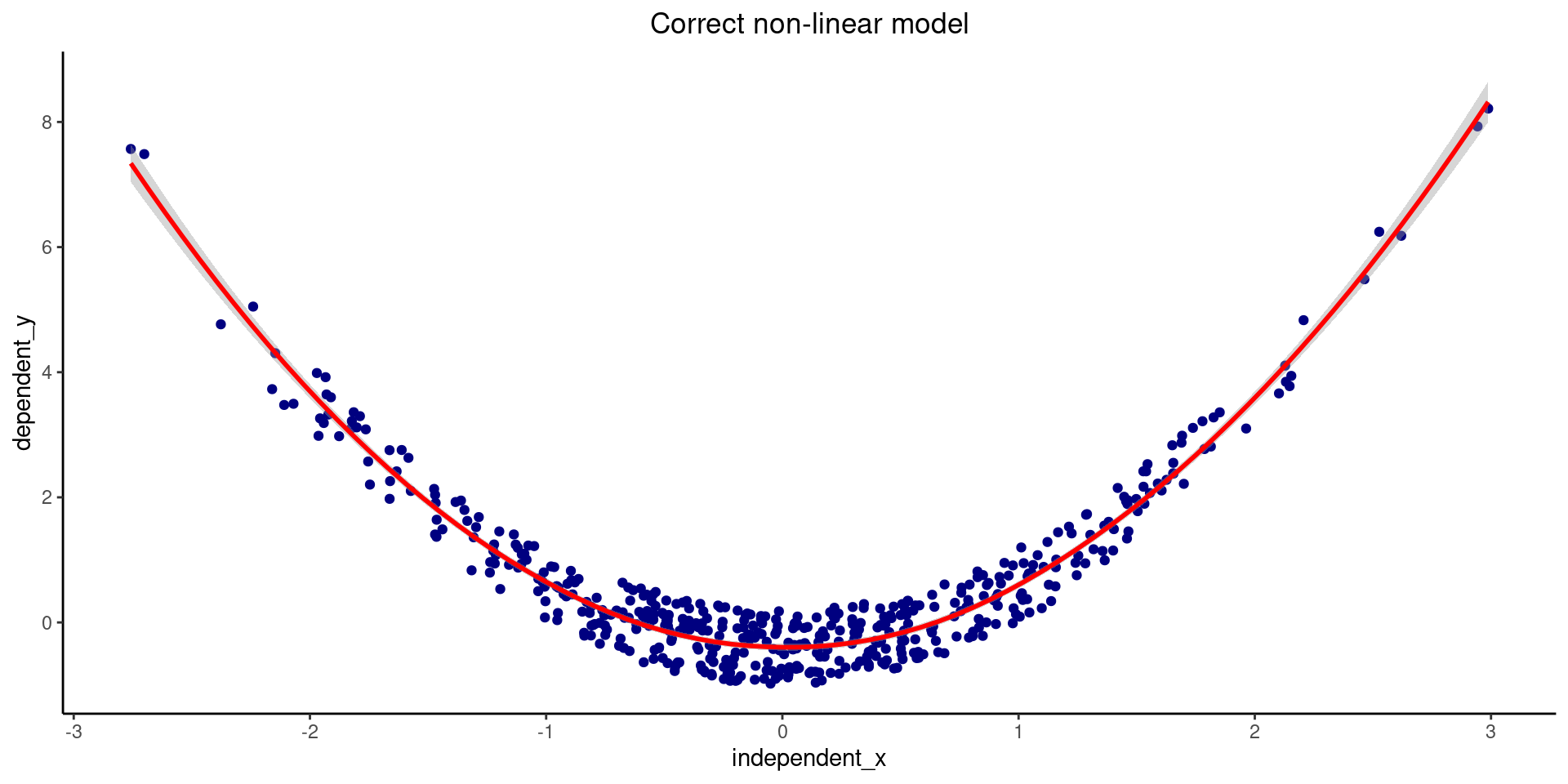
For example, we could check a case where we select the wrong model for the data, like the one showed below:
\[Y = \beta_{0} + \beta_{1}X_{1} + \epsilon\]
\[Y = \beta_{0} + \beta_{1}X_{1} + \beta_{2}X_{1}^2 + \epsilon\]
The world can show you interactions
Regression models are flexible in terms of interactions.
But, what is an interaction?: An interaction is what we call a moderated effect. Let’s see how it looks like:
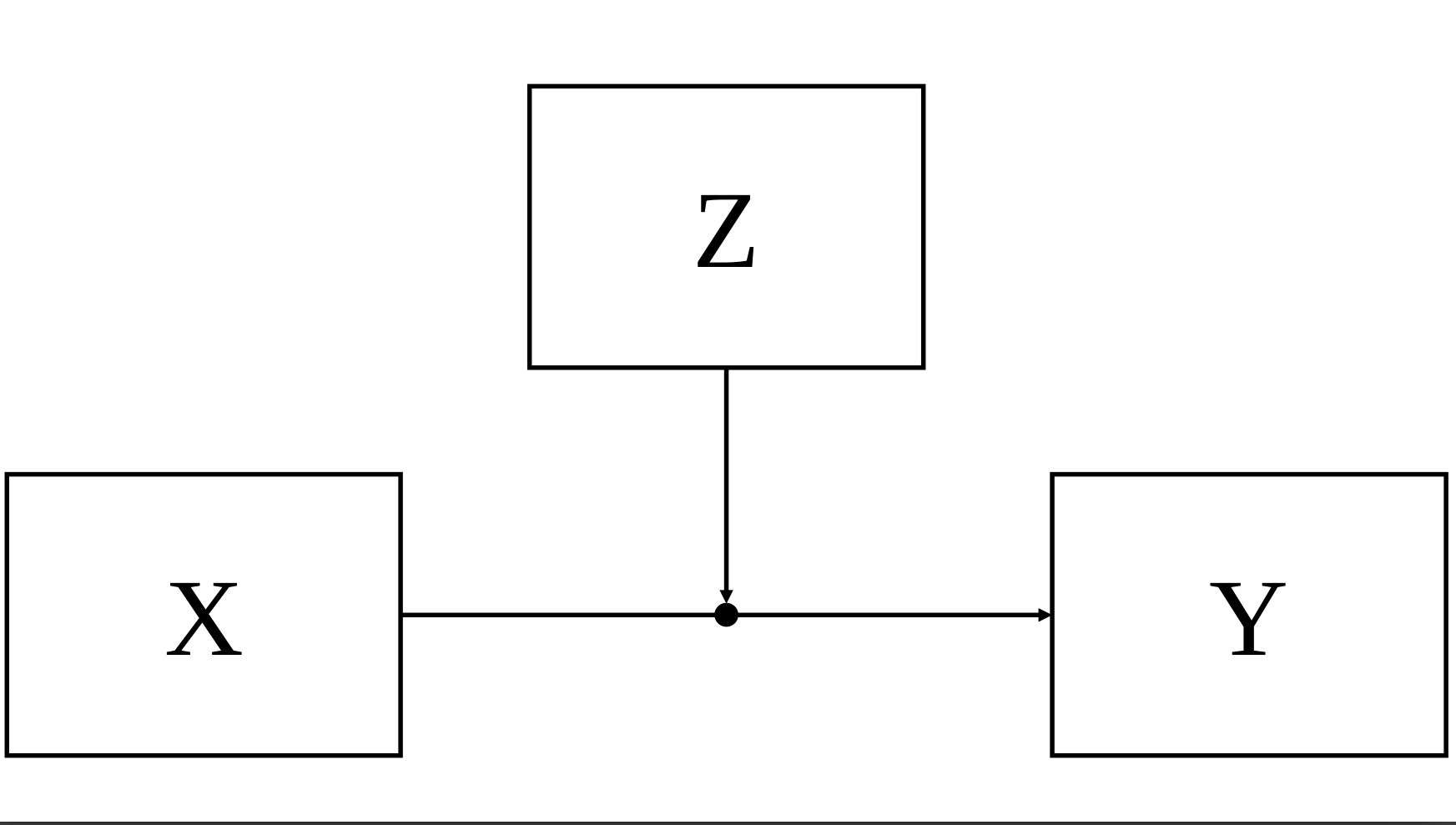
You can see in (Figure 1) there is a third variable Z affecting the relationship between X and Y. When this happens we say that the relationship between X and Y DEPENDS on Z
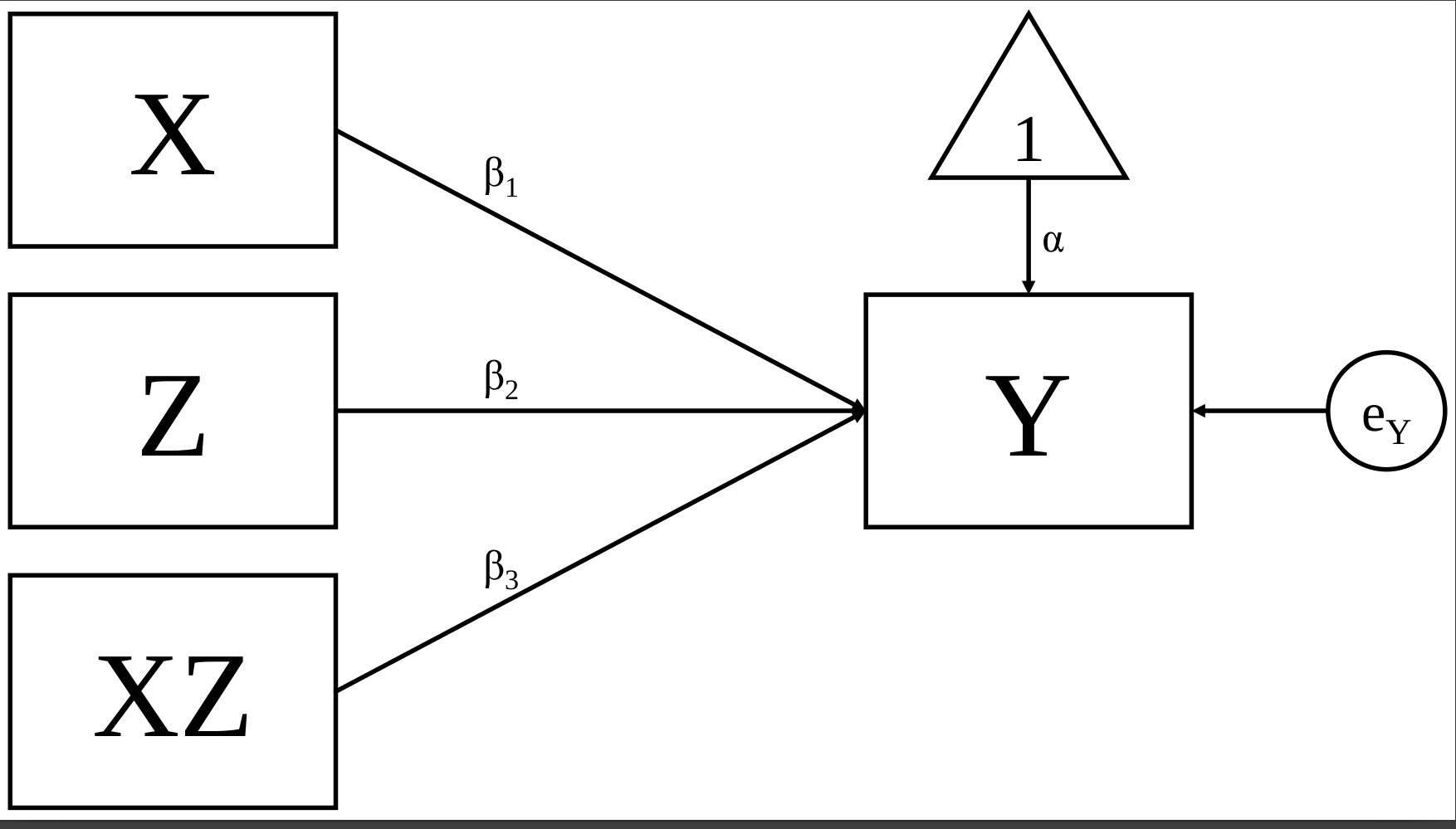
When we analyze an interaction we are estimating the product of a multiplication.
We can represent the Figure 2 in its mathematical form:
\[Y= \alpha + \beta_{1}X + \beta_{2}Z + \beta_{3}XZ + \epsilon_{i}\]
How do you interpret an interaction effect ?
The interpretation can be a little bit tricky. First, we need to understand the relation between depression and stress at each level of our moderator.
In our example, I selected social support as our moderator:

How do you interpret an interaction effect ?
Show the code
library(marginaleffects)
library(ggplot2)
### WE can use the package marginaleffects to
### generate slopes at different levels of
### the moderator
plot_predictions(fitModel_2,
condition = list("stress",
"socsup" = "threenum" ),
points = 0.5) +
theme_classic()+
ggtitle("Relationship between Stress and Depression at Social Support")+
theme(plot.title = element_text(hjust = 0.5))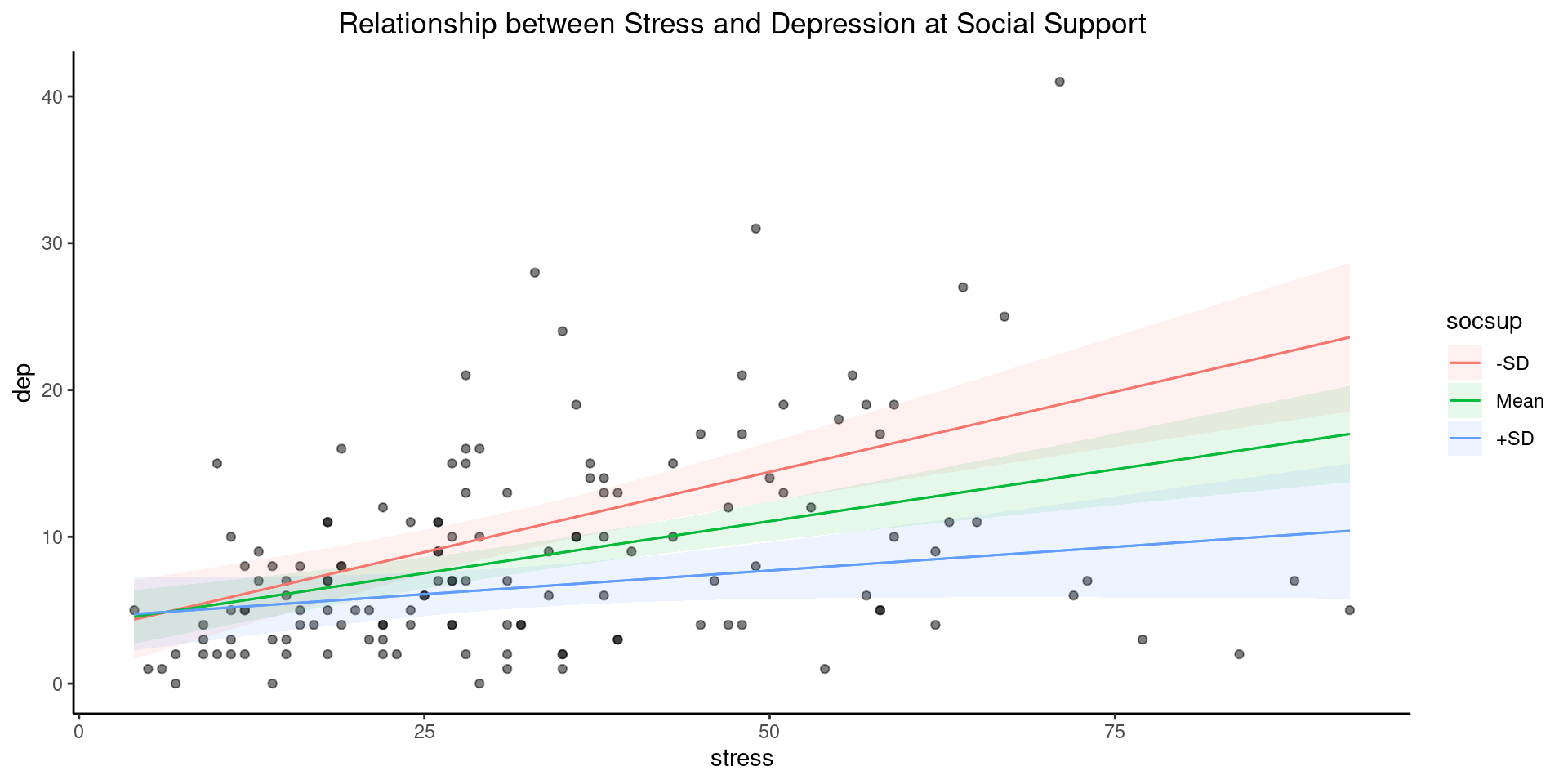
Simple slopes estimation: centering
- In our example, the moderator is social support. We can center our moderator at the mean, 1 SD above the mean, and 1 SD below the mean.
-In the following R chunk, I’ll create three new variables in the object stress which contains my data information. The three new variables are:
- SocialMean = \(socialSupport_{i} - mean(SocialSupport)\)
- SocialHigh = \(socialSupport_{i} - (mean(SocialSupport)+ sd(SocialSupport))\)
- SocialLow = \(socialSupport_{i} - (mean(SocialSupport) - sd(SocialSupport))\)
- Let’s check the new variables with a histogram:
Show the code
library(patchwork)
atMean <- ggplot(aes(x=socialMean), data = stress) +
geom_histogram(colour = 1,
fill = "white",
binwidth = 1) +
theme_classic()
atHigh <- ggplot(aes(x=socialHigh), data = stress) +
geom_histogram(colour = 1,
fill = "white",
binwidth = 1) +
theme_classic()
atLow <- ggplot(aes(x=socialLow), data = stress) +
geom_histogram(colour = 1,
fill = "white",
binwidth = 1) +
theme_classic()
atMean/(atHigh+atLow)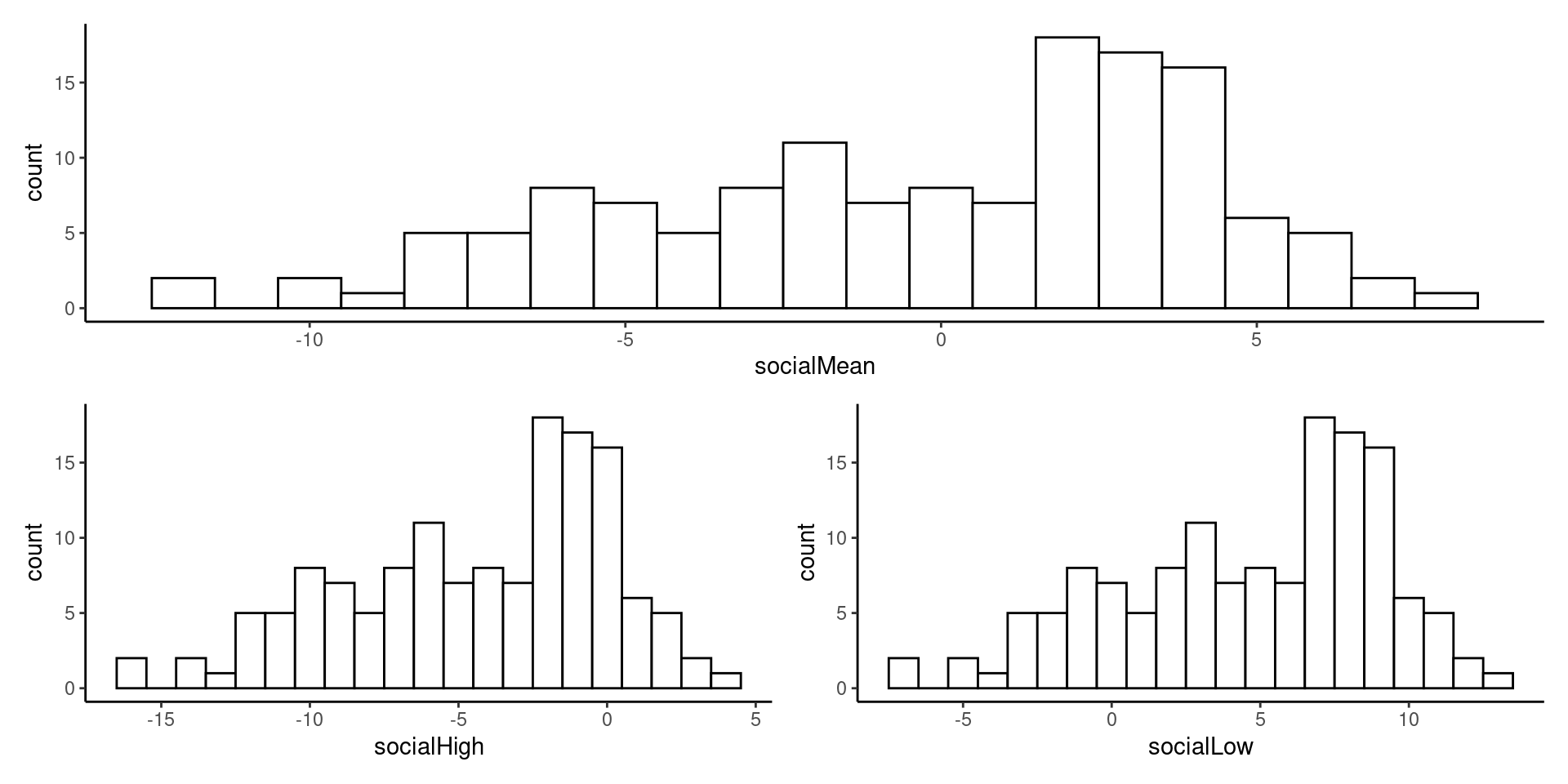
- Now, we can use this three new computed centered variables to estimate our simple slopes at the mean, \(mean + 1SD\), and \(mean - 1SD\).
Simple slopes: Johnson-Neyman technique in R
The Johnson-Neyman technique is implemented in the
Rpackagerockchalk. There are more packages performing this strategy.You first need to estimate your moderated regression model, this means a model with at least one interaction term.
Secondly you can estimate the simple slopes, and the region of significance.
Show the code
JOHNSON-NEYMAN INTERVAL
When socsup is OUTSIDE the interval [23.78, 50.44], the slope of stress is
p < .05.
Note: The range of observed values of socsup is [8.00, 28.00]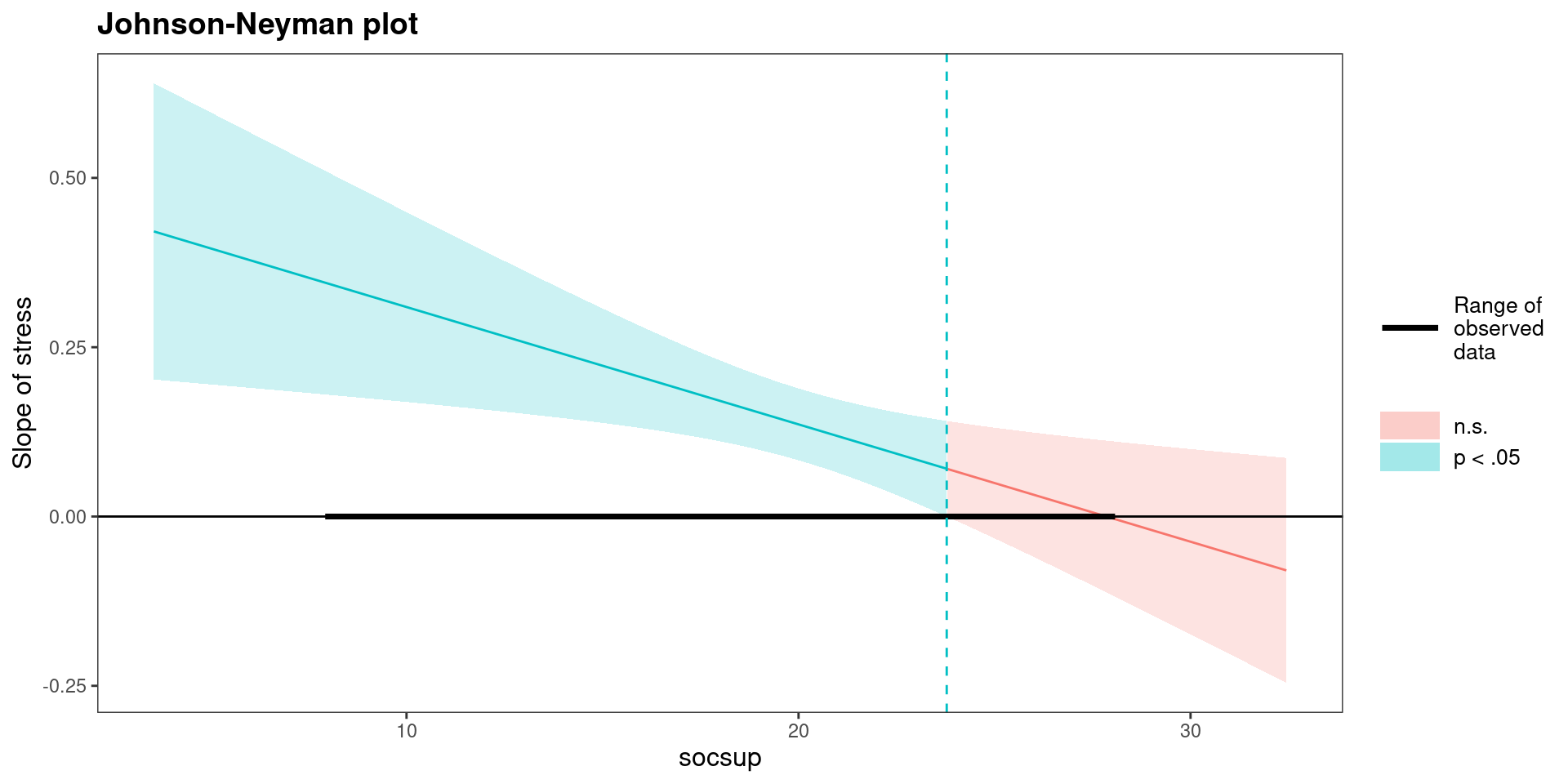
SIMPLE SLOPES ANALYSIS
Slope of stress when socsup = 15.24283 (- 1 SD):
Est. S.E. t val. p
------ ------ -------- ------
0.22 0.04 5.26 0.00
Slope of stress when socsup = 19.68794 (Mean):
Est. S.E. t val. p
------ ------ -------- ------
0.14 0.03 5.24 0.00
Slope of stress when socsup = 24.13306 (+ 1 SD):
Est. S.E. t val. p
------ ------ -------- ------
0.06 0.04 1.73 0.09Acknowledgement
This lecture was created based on the materials created by Kyle M. Lang (2016) and Mauricio Garnier-Villareal (2020)
![]()
