setwd("C:/Users/emontenegro1/Documents/MEGA/stanStateDocuments/PSYC3000/lecture5")
rum <- read.csv("ruminationComplete.csv")
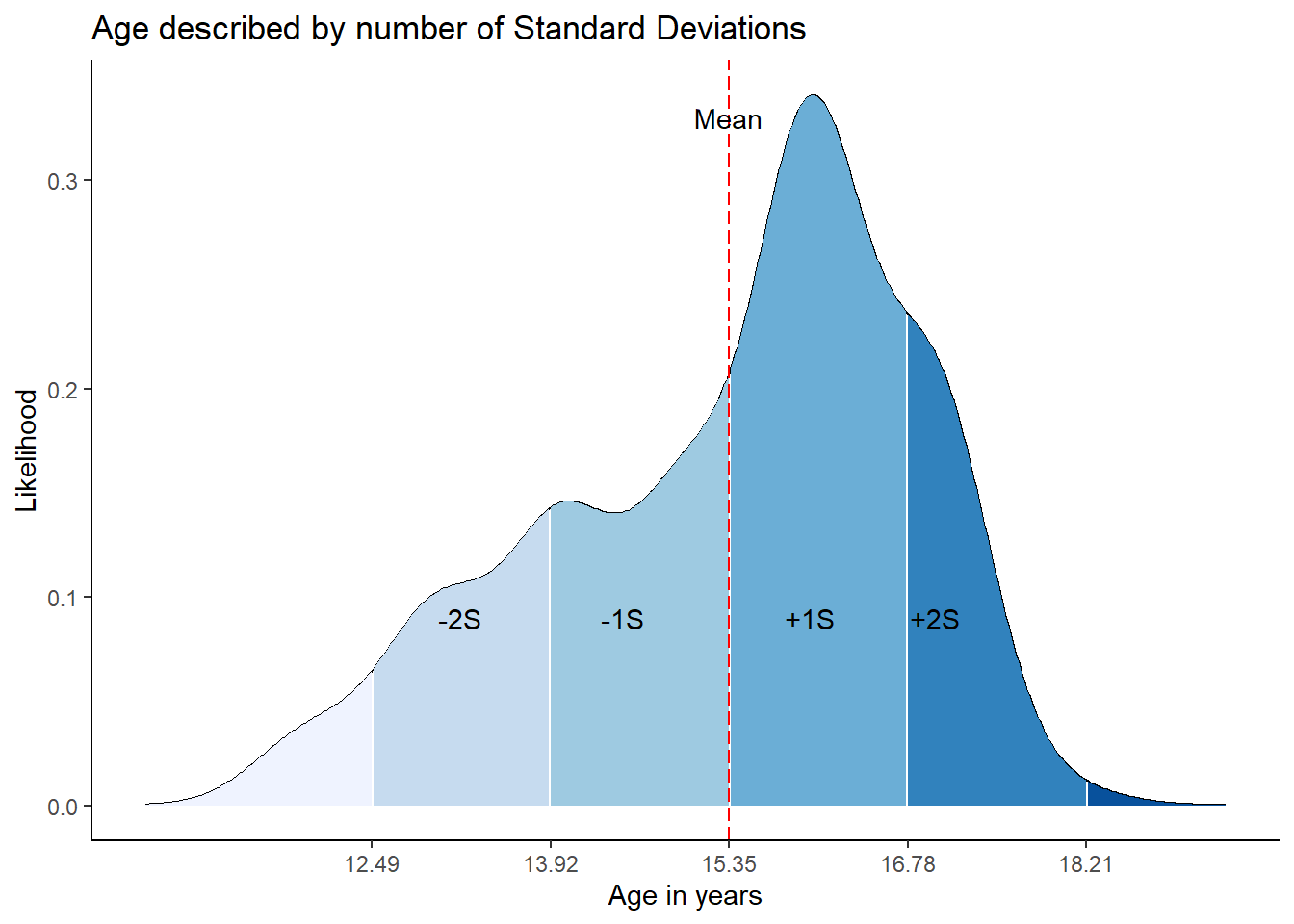
mean(rum$age)[1] 15.34906APA Style
Let’s do it by hand:
As you might remember, the mean is strongly affected by the extreme cases, whereas the median is more “robust” to extreme cases. This means the median is less affected by extreme values.
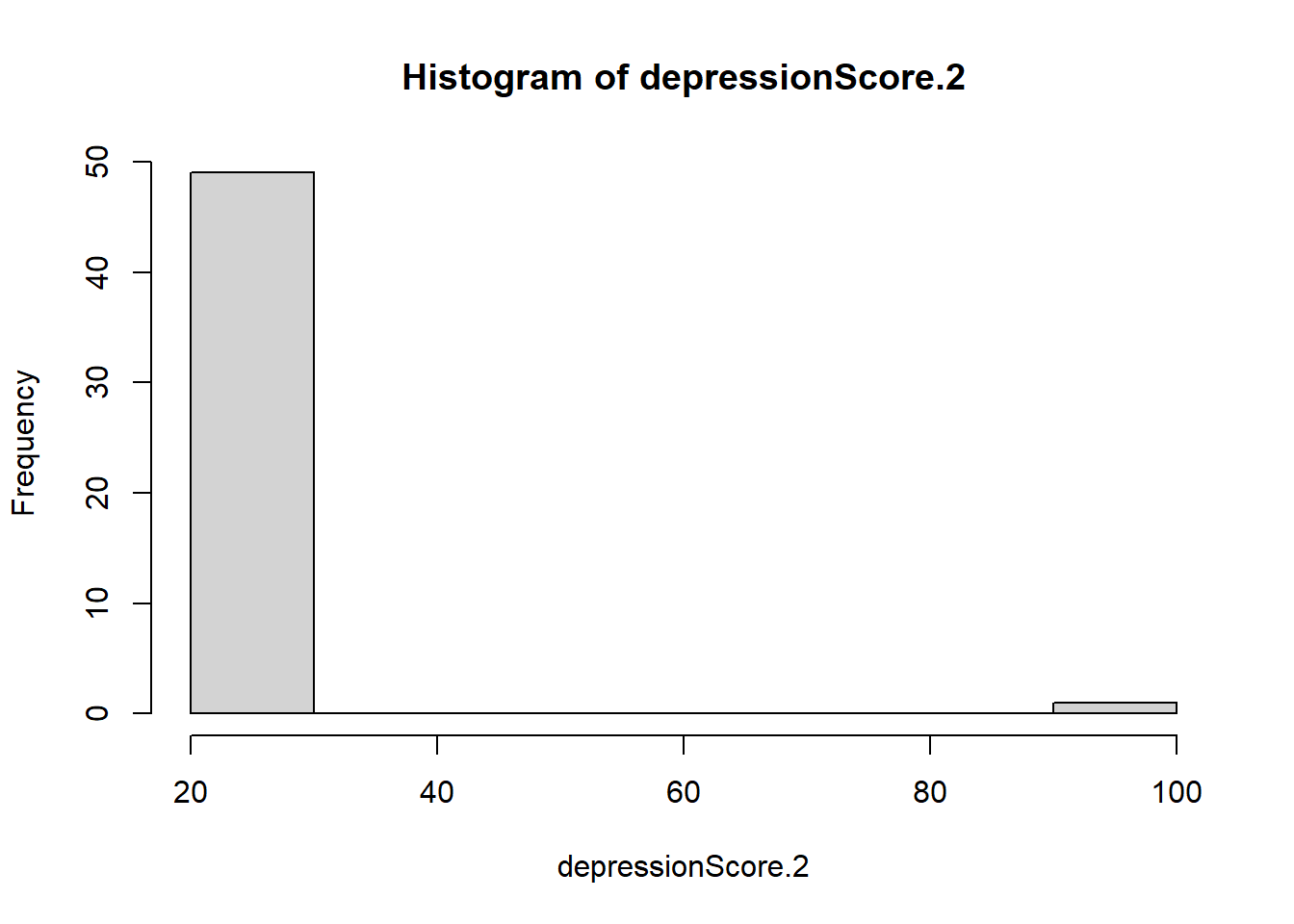
Let’s use simulation to find out if it is true, imagine you have data related to a depression score:
set.seed(1256)
M <- 25
SD <- 1
n <- 50
## Simulated depression score
depressionScore <- rnorm(n = n, mean = M, sd = SD)
hist(depressionScore)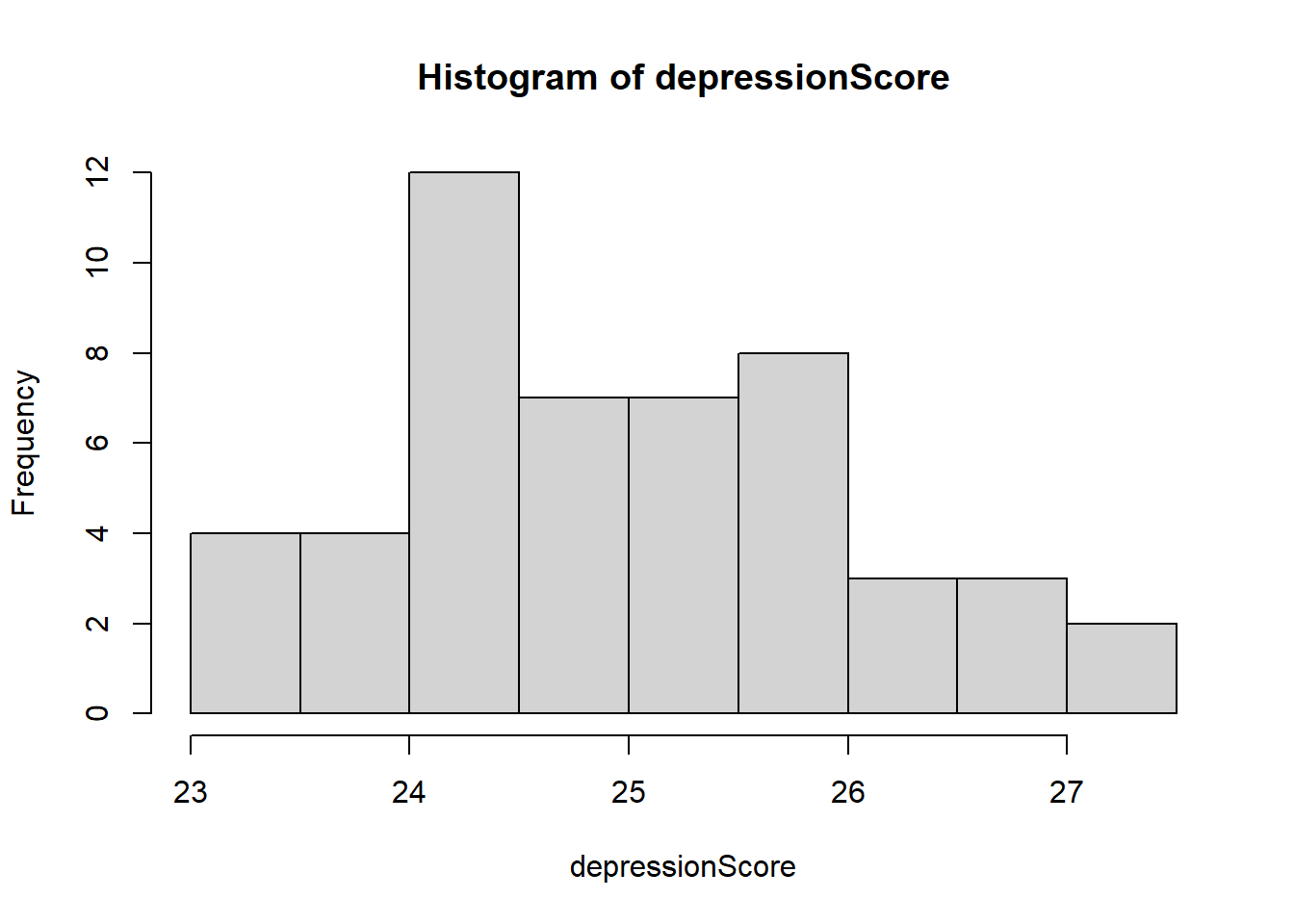
Mean before the extreme case: 24.97403Mean after the extreme case: 26.48716Median before the extreme case: 24.82834Median after the extreme case: 24.89818Summary() function as a good optionR we can count on a handy function to describe a distribution, this function is summary().library(ggplot2) ### package to create pretty plots
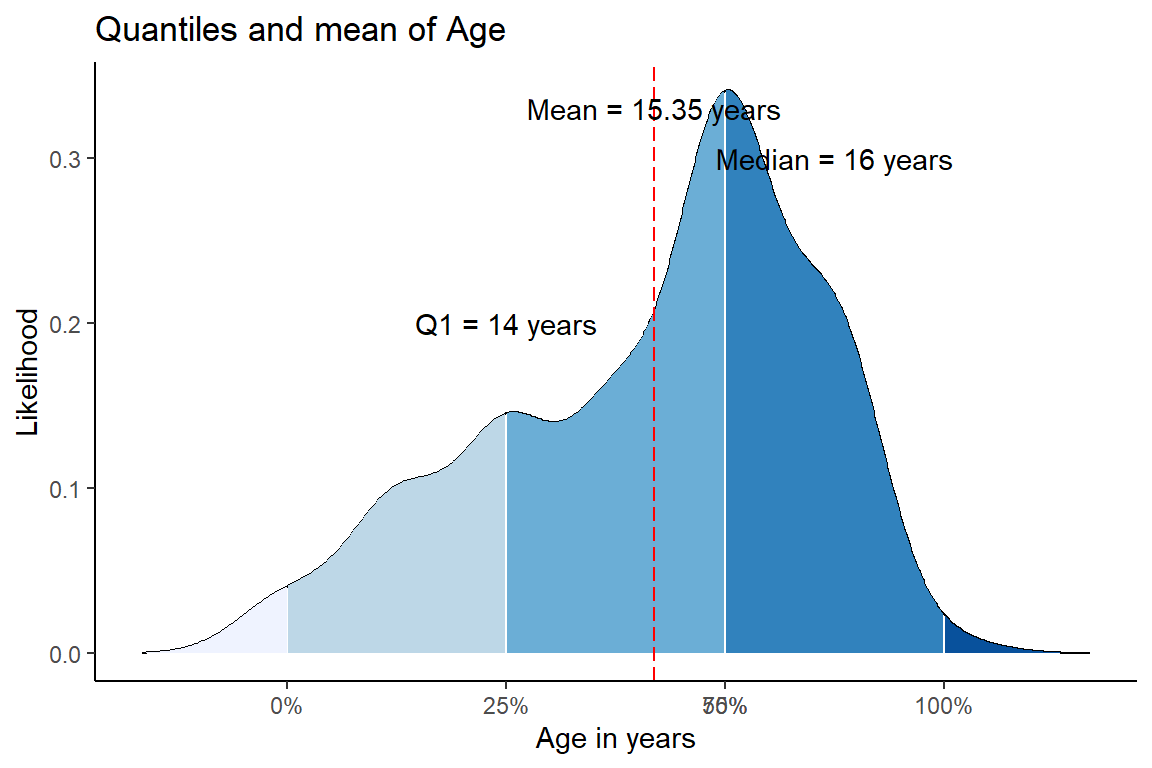
dens <- density(rum$age)
df <- data.frame(x=dens$x, y=dens$y)
probs <- c(0, 0.25, 0.5, 0.75, 1)
quantiles <- quantile(rum$age, prob=probs)
df$quant <- factor(findInterval(df$x,quantiles))
figure <- ggplot(df, aes(x,y)) +
geom_line() +
geom_ribbon(aes(ymin=0, ymax=y, fill=quant)) +
scale_x_continuous(breaks=quantiles) +
scale_fill_brewer(guide="none") +
geom_vline(xintercept=mean(rum$age), linetype = "longdash", color = "red") +
annotate("text", x = 14, y = 0.2, label = "Q1 = 14 years") +
annotate("text", x = 17, y = 0.3, label = "Median = 16 years") +
annotate("text", x = 15.35, y = 0.33, label = "Mean = 15.35 years") +
ylab("Likelihood") +
xlab("Age in years")+
ggtitle("Quantiles and mean of Age")+
theme_classic()As always we can study an example:
Hospital Example
library(ggplot2) ### <- this is a package in R to create pretty plots.
set.seed(359)
### Non-hospital observations
### Mean or average in Kg
Mean <- 65
## Standard Deviation
SD <- 1
## Number of observations
N <- 300
### Generated values from the normal distribution
data_1 <- rnorm(n = N, mean = Mean, sd = SD )
data_1
### Hospital group
### Mean or average in Kg
Mean <- 90
## Standard Deviation
SD <- 10
## Number of observations
N <- 300
### Generated values from the normal distribution
data_2 <- rnorm(n = N, mean = Mean, sd = SD )
data_2
dataMerged <- data.frame(
group =c(rep("College", 300),
rep("Hospital", 300)),
weight = c(data_1, data_2))
ggplot(dataMerged , aes(x=weight, fill=group)) +
geom_density(alpha=.25) +
theme_bw()+
labs(title = "College and Hospital Weight Density Function") +
xlab("Weight (kg)") +
ylab("p(y) or likelihood")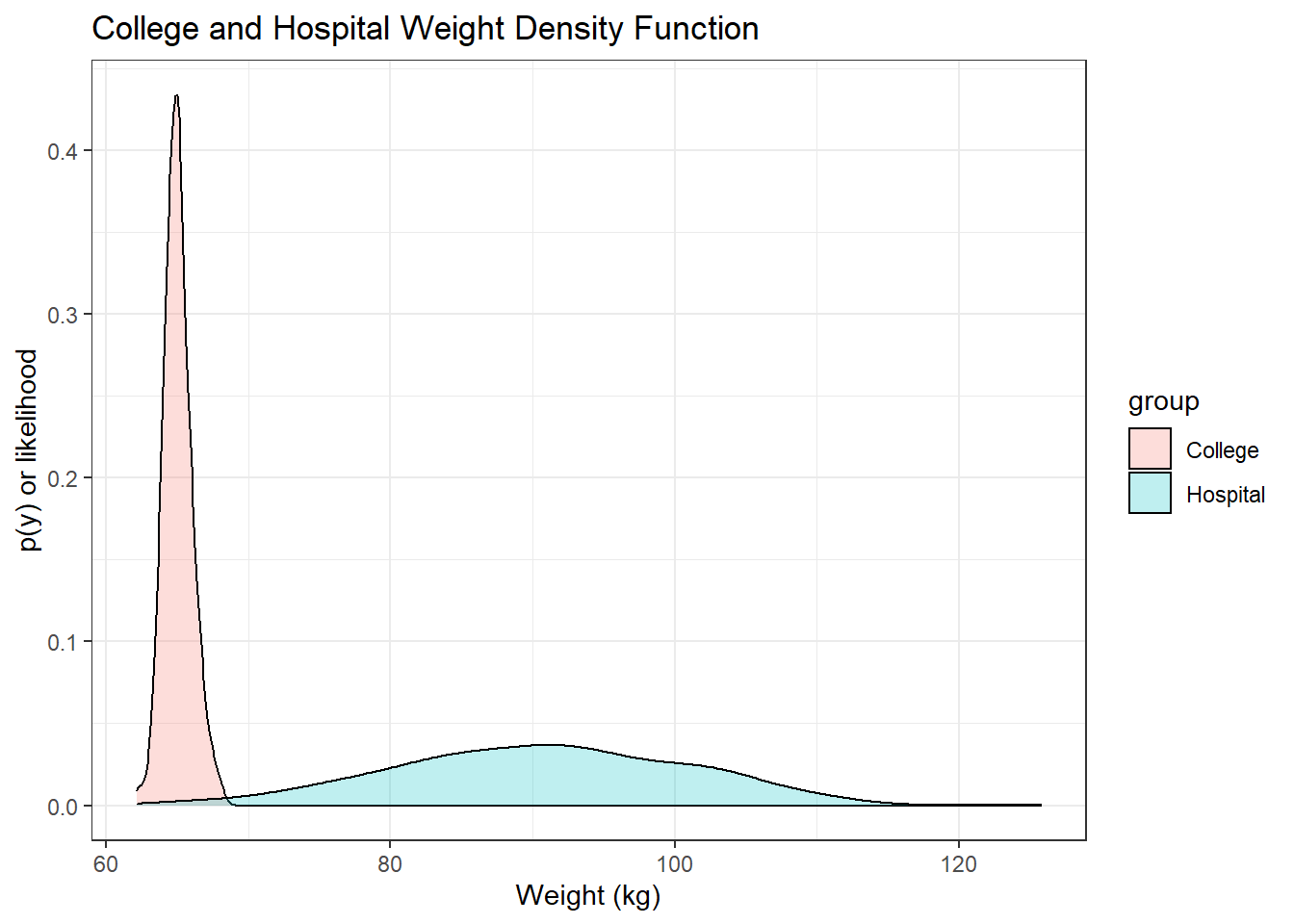
mpg variable inside the data mtcars:As the name says, we are like “stacking” the whole density, therefore it changes the shape of the curve, but at the end is the same information in a different metric.
In fact, you get the derivative of a CDF, th calculation will give you the PDF back.
But no worries, I won’t ask you to do it… you are safe!
All continuous distributions will have a CDF, and we are going to use very often the normal CDF.
The normal distribution is also called “Gaussian Distribution” , I prefer this name instead of “normal distribution”.
Anyhow, let’s check some properties here.
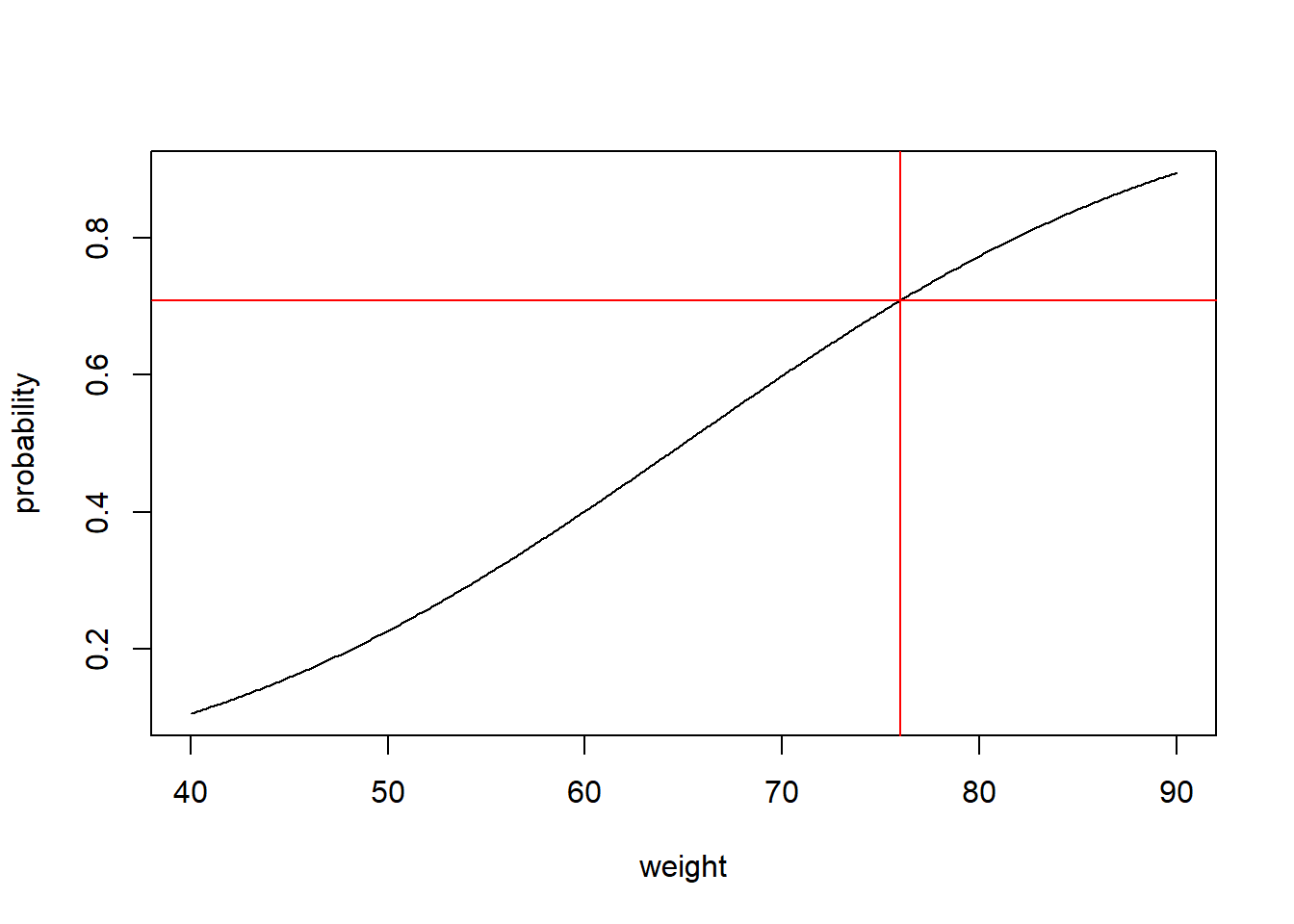
We can also understand the importance of the Gaussian CDF using R:
## sequence of x-values
justSequence <- seq(-4, 4, .01)
#calculate normal CDF probabilities
prob <- pnorm(justSequence)
#plot normal CDF
plot(justSequence ,
prob,
type="l",
xlab = "Generated Values",
ylab = "Probability",
main = "CDF of the Standard Gaussian Distribution")
abline(v=1.96, h = 0.975, col = "red")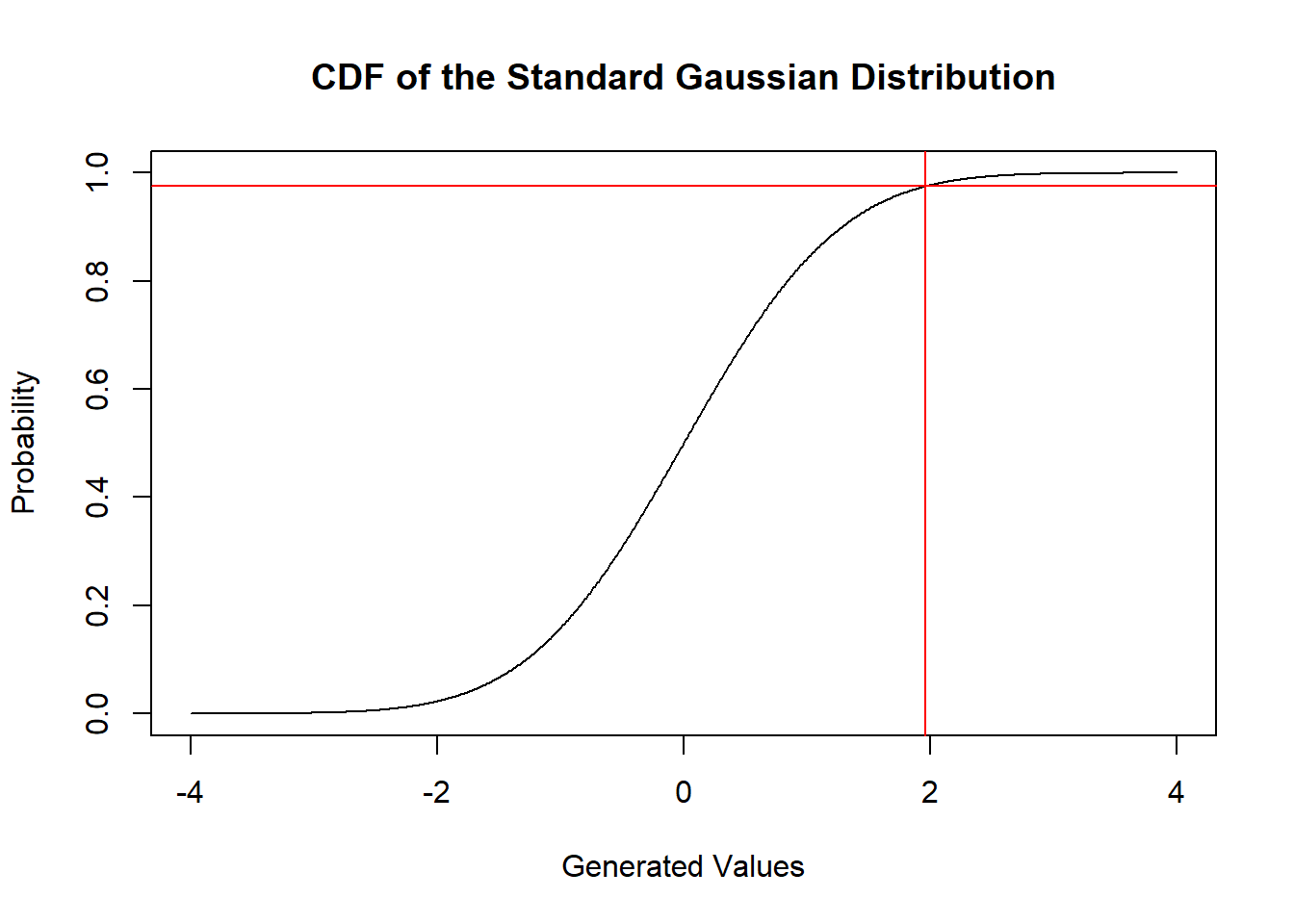
Let’s do something more intersting, remember the example of weight where we simulated the weight of two groups: hospital patients vs. college students?
We could now get the probability of observing a particular value.
Let’s imagine again that the distribution of weight among college students has a mean of 65 kg, and standard deviation of 20 kg.
I left some concepts behind because I got excited talking about the CDF.
One important concept to describe a distribution is skewness.
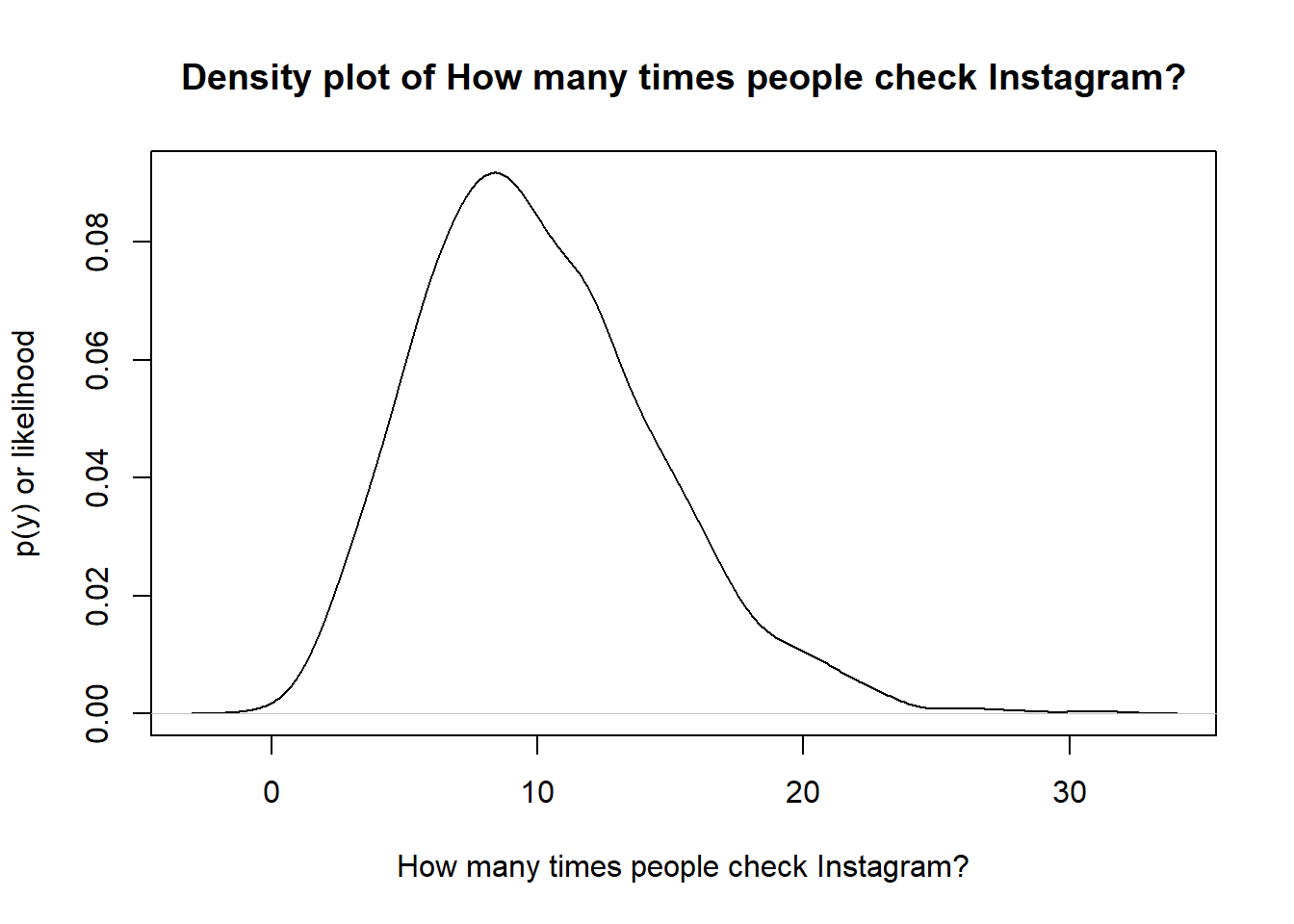
set.seed(5696)
N <- 1000
### Number of times people check Instagram
weight <- rnbinom(N, 10, .5)
plot(density(weight, kernel = "gaussian" ),
ylab = "p(y) or likelihood",
xlab = "How many times people check Instagram?",
main = "Density plot of How many times people check Instagram?")