graph TD
A[GLM] --> B(ANOVA)
A[GLM] --> C(MANOVA)
A[GLM] --> D(t-test)
A[GLM] --> E(Linear Regression)
Correlation and Regression Models
Part 3: ANOVA and The General Linear Model
Let’s make up time for ANOVA (cont.)
- In this estimation we calculate the difference of each observation from the group mean where the observation is located. So, for instance if Katie was in the divorced group, then we could compute: \(wage_{katie} - mean(wage_{divorced})\). This is an indicator of variation not explained by the model. This means, ANOVA does not explain what happens within each group’s variation, it accounts for the between group variation.
Time for examples !
Show the code
ggplot(data = Wage,aes(x=maritl, y=wage, fill=maritl)) +
geom_boxplot() +
stat_summary(fun="mean", color="red")+
scale_fill_viridis(discrete = TRUE, alpha=0.6, option="A") +
theme_classic()+
theme(legend.position = "none")+
labs(x= "Marital Status", y= "Wage", title = "Boxplot of Wage by Marital Status")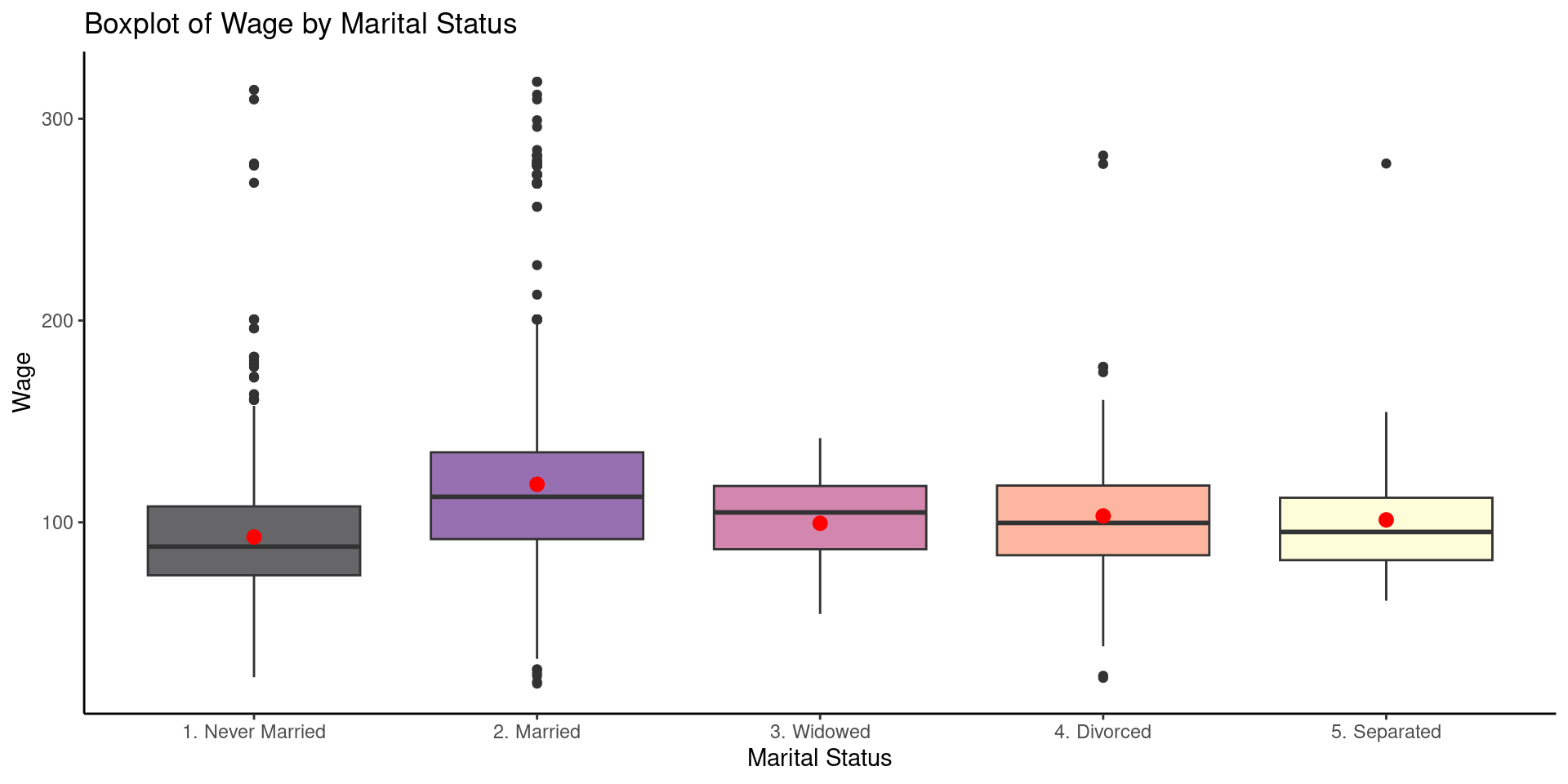
F ratio estimation
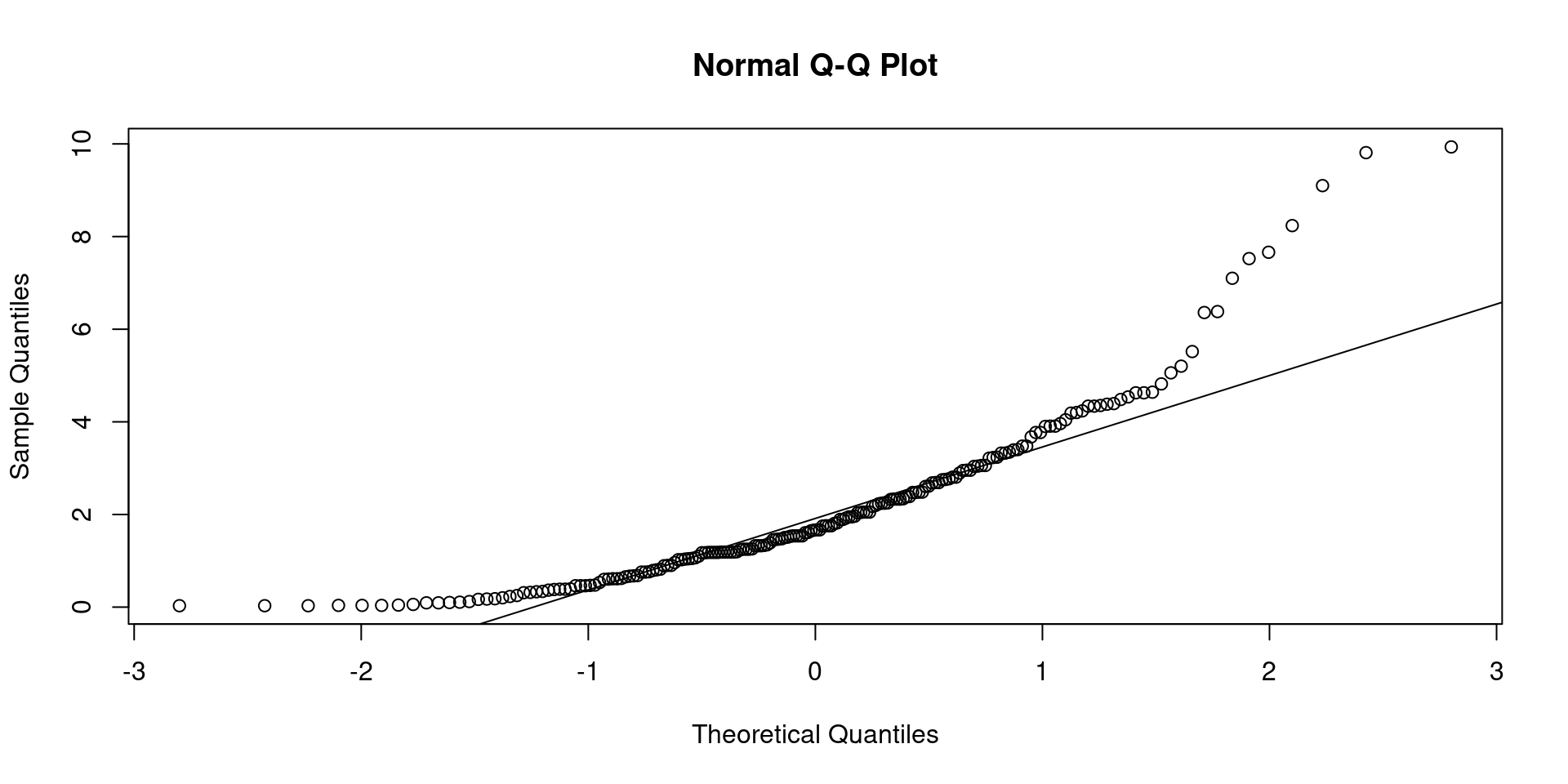
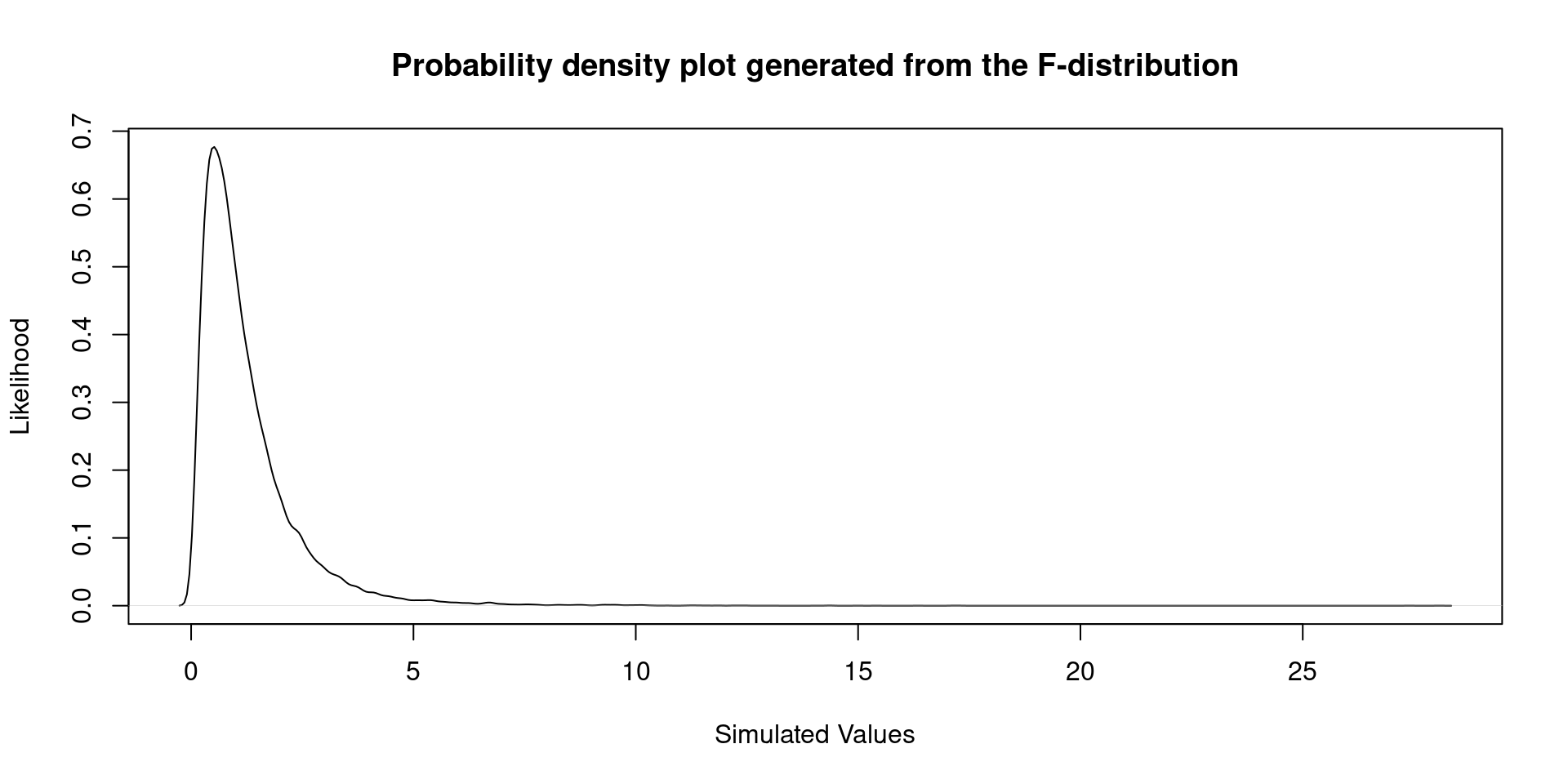
- In previous classes we studied the \(t\)-test. Hopefully, you remember the \(t\)-distribution:
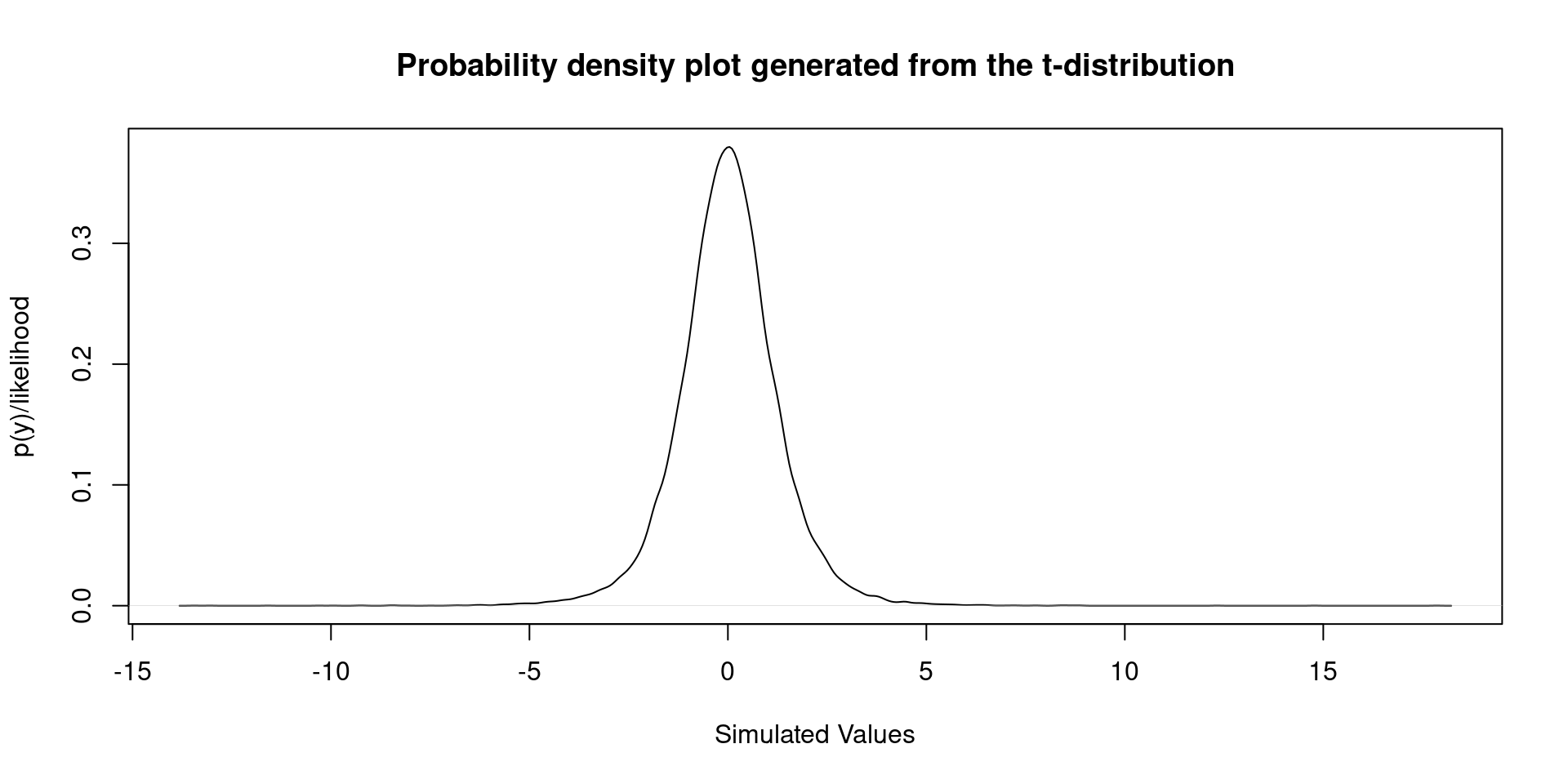
F ratio estimation
Just another F distribution
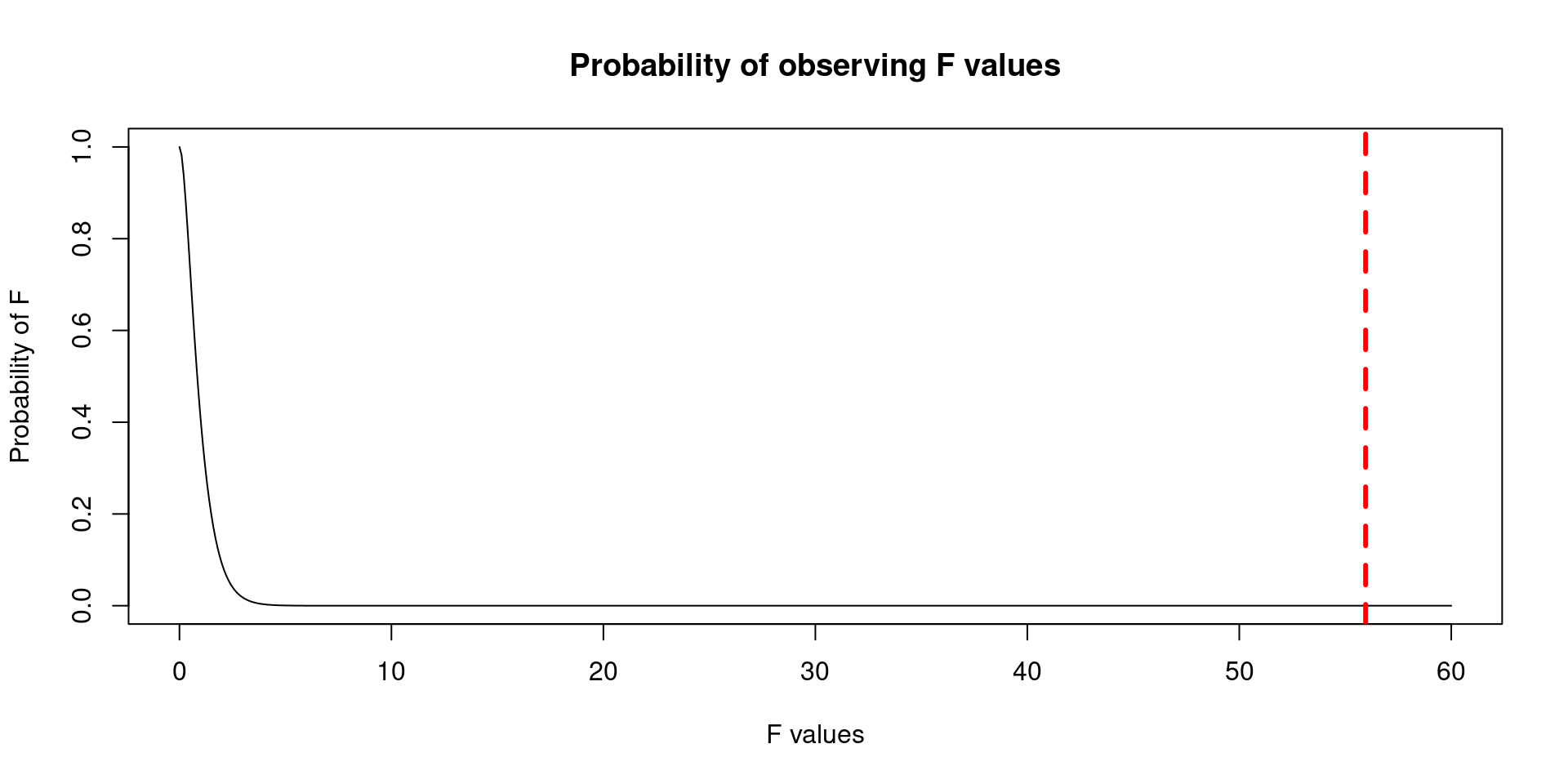
F ratio estimation: let’s go to the point
- The Cumulative Density Function of the F distribution will help us to estimate the probability of seeing a number as extreme as: 55.96. The red line corresponds to the location of 55.96.
ANOVA and Classical Regression Model
- In the context of regression we can plot the predicted values called \(\hat{y}\) (“yhat”), versus the residuals
Show the code
newWage <- Wage %>% mutate(married = ifelse(maritl == "2. Married", 1,0),
widowed = ifelse(maritl== "3. Widowed", 1,0),
divorced = ifelse(maritl== "4. Divorced", 1,0),
separate = ifelse(maritl== "5. Separated", 1,0))
fitModel <- lm(wage ~ married + widowed + divorced + separate, data = newWage)
y.hat = fitModel$fitted.values
resid = fitModel$residuals
plot(y.hat, resid,
xlab = "Predicted wage",
ylab = "residuals")
abline(h=0)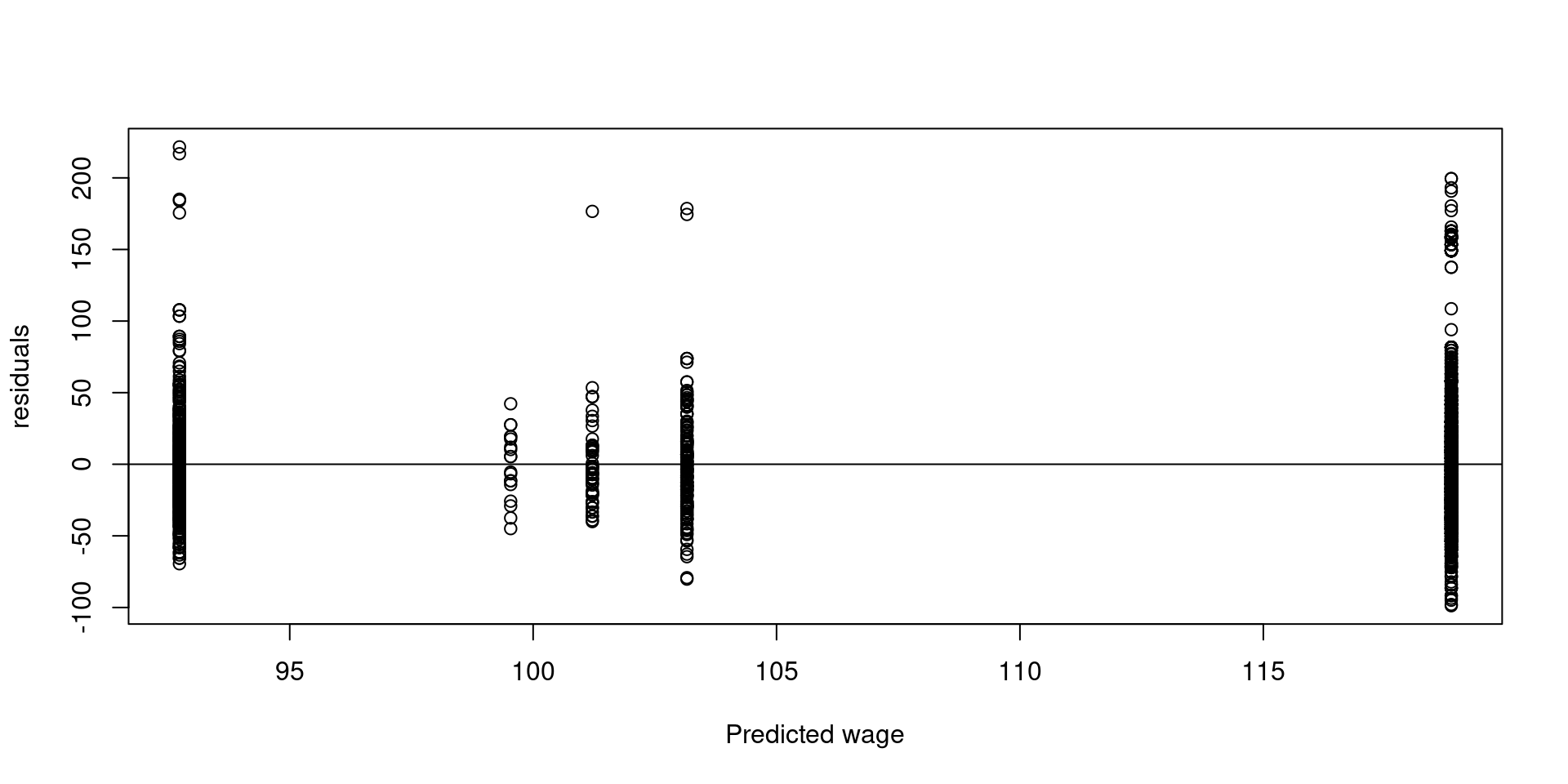
ANOVA and Classical Regression Model
In the previous plot we can see more variability when the predicted wage is high. We can also see differences in variability in the lower income groups.
We can plot similar information, but this time let’s use the absolute residuals:
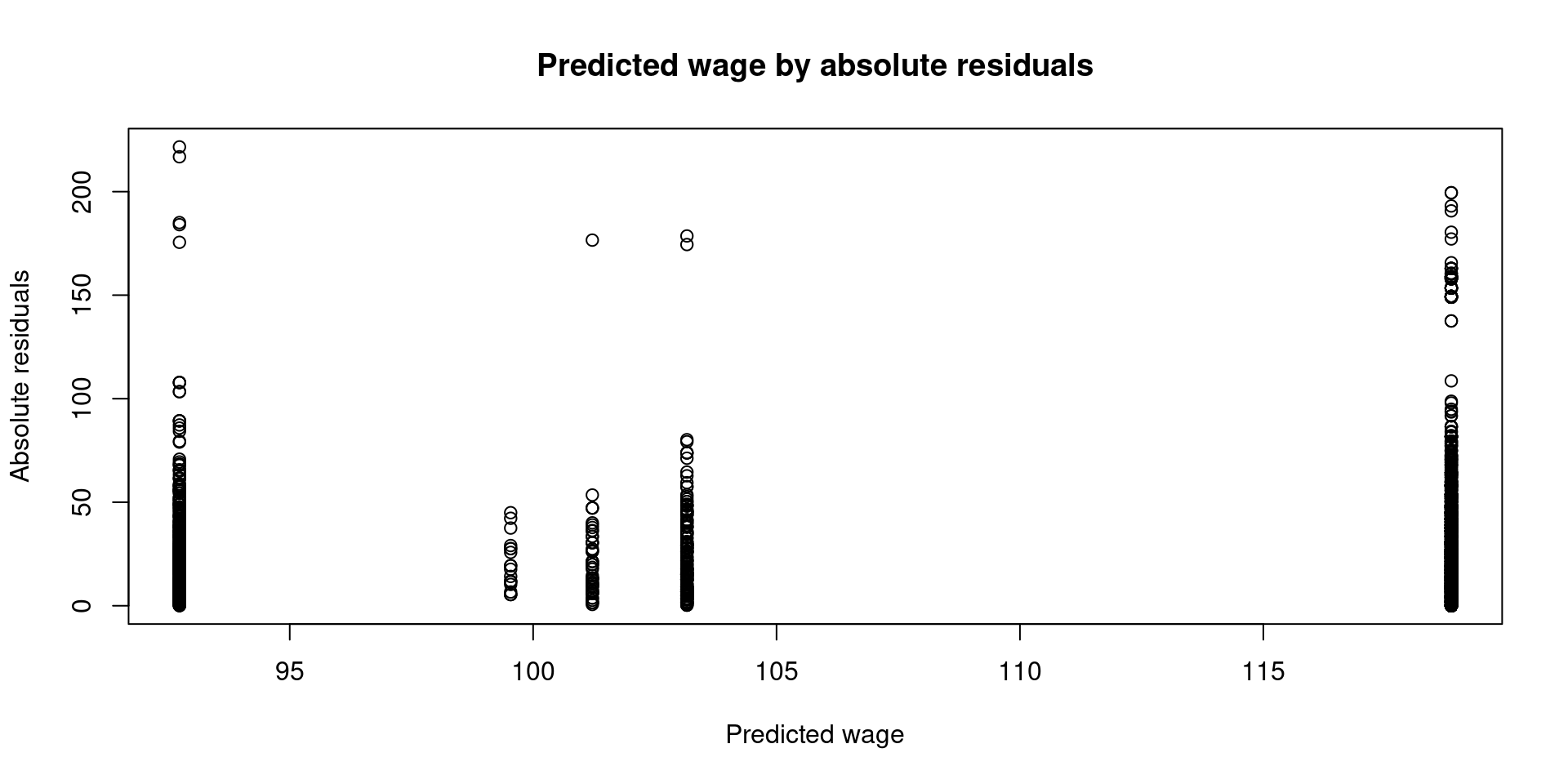
Similar pattern, there is more variability in the groups where men earn more money. But is this bad for the linear model?
It depends. We need to think if this is just part of the data generating process.
ANOVA and Classical Regression Model
- We can check the constant variance assumption in the context of a continuous predictor. This example only applies to Linear Regression, it won’t work with ANOVA because ANOVA only supports nominal predictors (groups).
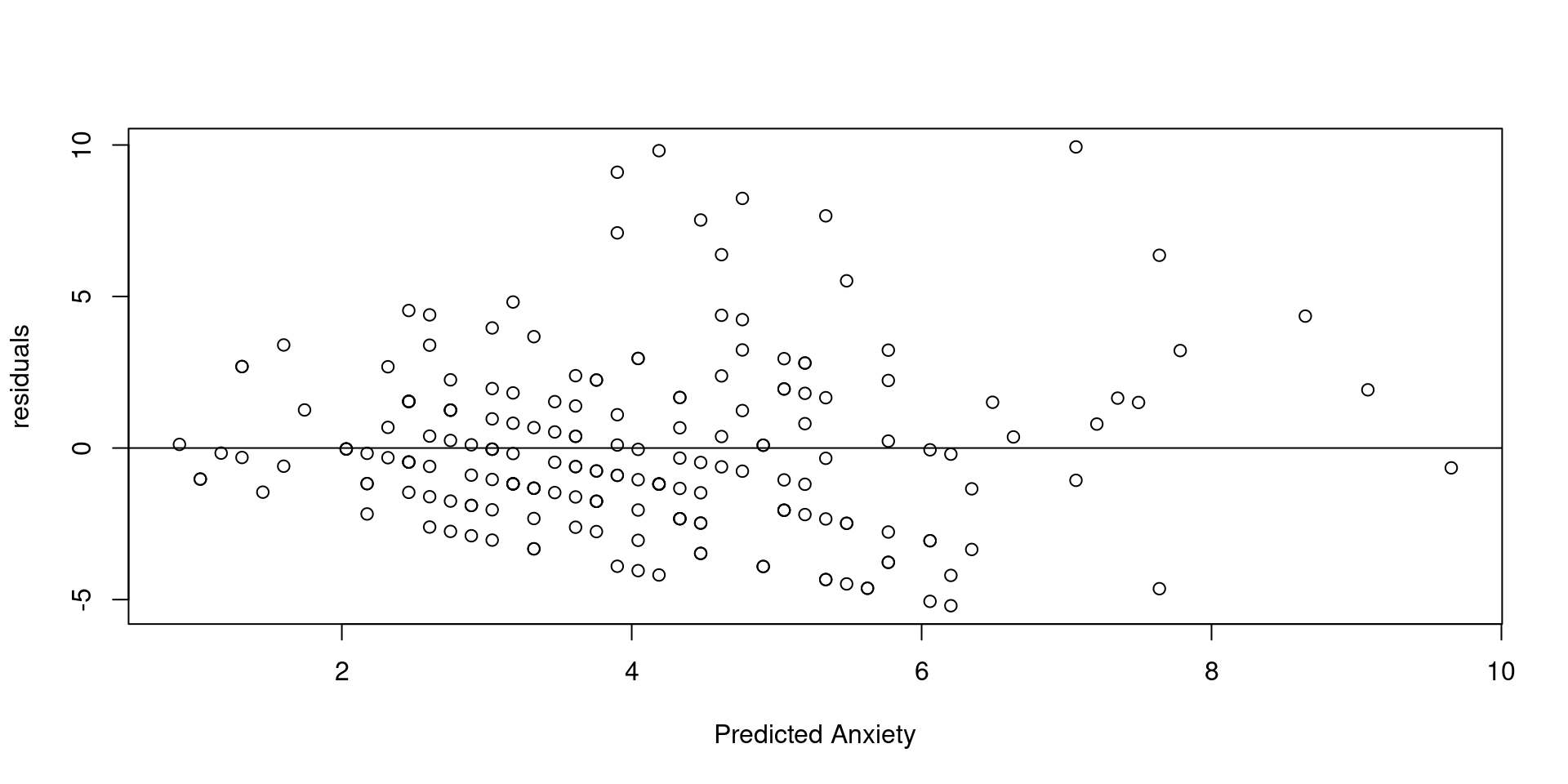
Classical Regression Model: normality assumption